
Machine Learning/Software Engineer
Hello, world!
I’m a Machine Learning Engineer and Engineering Lead with extensive experience building large-scale data products across the tech industry — including work on experimentation, personalization, and dynamic pricing systems for one of Europe’s biggest ride-hailing platforms.
My work sits at the intersection of machine learning engineering, experimentation, and applied research — designing efficient, scalable ML pipelines for production while staying close to the latest developments in the field. Over the years, I’ve worked on projects spanning CTR prediction, recommender systems, fine-tuned embedding models, and natural language processing.
I am also the owner of Eleni Markou LP, through which I provide consulting services in software engineering, data science, and machine learning, including application development, and systems consulting.
Beyond work, I’m passionate about travel, photography, and local food — I love exploring new places and documenting small details that tell stories. Occasionally, I write about new technologies I experiment with and the challenges (and lessons) that come with them.
For more information about my work or consulting services, feel free to reach out or take a look at my CV.
Education



National Technical University of Athens (NTUA)
M.Eng. in Electrical and Computer Engineering
Professional Experience






For more details, please see my full CV (PDF).
Projects

Data Analytics and Research Assessment: A Case Study in Health and the Diseases of the Circulatory System
Joint work with Marianna Klironomou
Advised by Dr. Haris Papageorgiou
The project was developed under the auspices of "Data4Impact" H2020 project, which aimed to access the performance of EU and national research and innovation system. In collaboration with "Athena" Research Center, the project attempts to employ a network approach on the matter and develop a multi-layer graph infrastructure in order to assess the societal impact of health-related research in Europe for the past 10 years using Data Mining and Machine Learning techniques.
[Data4Impact Homepage] [Deliverable (PDF)]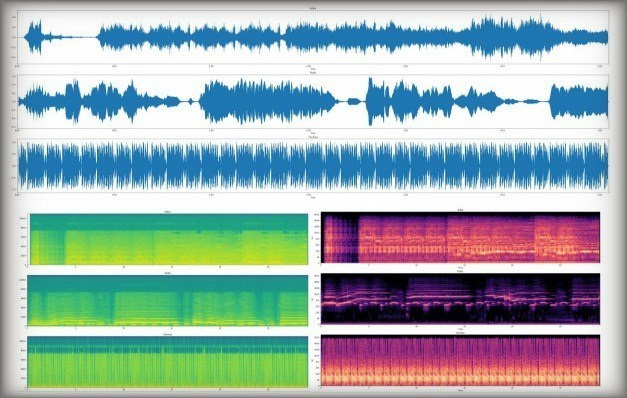
Automatic Tagging of Audio Clips with Descriptive Tags
Advised by Dr. Haris Papageorgiou
We developed a Convolutional Neural Network (CNN) that would take the spectrograms of the initial audio clips and perform a multi-label classification task with 50+ potential tags. This way, we easily (1) label audio clips avoiding hand-engineered features like Mel Frequency Cepstral Coefficients (MFCCs) which require expert knowledge and (2) estimate the similarity between audio clips or music songs (by computing the number of overlapping tags).
[GitHub Repository]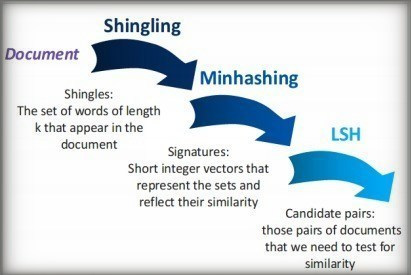
Computing similairty among textual documents in newspaper articles
By subsequently applying shingling (on a word level), minhashing and Locality Sensitive Hashing (LSH) we managed to be able to compute Jaccard similarity among text corpora. This way, we can (1) retrieve similar documents for any given document and (2)effectively apply the same methodology in significantly large textual collections.
[GitHub Repository]Blog Posts

Machine Learning Alogrithms you need to know
Decision trees vs. clustering algorithms vs. linear regression: Which machine learning algorithms should you use, why, and when?
Imagine you have some data-related problem that you want to solve. You have heard of all the amazing things that machine learning algorithms can achieve and want to try it for yourself — but you have no prior experience or knowledge in this area. You start googling some terms like “machine learning models” and “machine learning methodologies,” but after some time, you find yourself ready to give up, completely lost somewhere between the different algorithms.
Read More at DZone
How to Work With Pivot Tables in PostgreSQL, Amazon Redshift, BigQuery, and MS SQL Server
During the past few years, some well-known database systems have implemented functions for pivot table creation,
saving us from the development of complicated queries.
All of us have at some point worked with some spreadsheet software, like Excel or Google Sheets, or BI tools and we have to admit that they offer certain functionalities that are very handy when it comes to data presentation and reporting, like the so-called pivot tables. Since many business applications require some sort of pivot tables, I am sure many of you have found themselves struggling with how to satisfy these requirements using a database instead of a spreadsheet.
Read More at DZone
SQL Database, Table, and Data Partitioning: When and How to Do It
As with everything in life, it seems that table partitioning comes at a cost. Nevertheless,
if implemented in the right way at the right time, it can be a lifesaver.
When I first came across table partitioning and started searching, I realized two things. First, it is a complex operation that requires good planning. Second, in some cases, it can be proven extremely beneficial, while in others, it can be a complete headache.
Read More at DZone